In today's post we will try to cover very interesting and important topic: distributed system tracing. What it practically means is that we will try to trace the request from the point it was issued by the client to the point the response to this request was received. At first, it looks quite straightforward but in reality it may involve many calls to several other systems, databases, NoSQL stores, caches, you name it ...
In 2010 Google published a paper about Dapper, a large-scale distributed systems tracing infrastructure (very interesting reading by the way). Later on, Twitter built its own implementation based on Dapper paper, called Zipkin and that's the one we are going to look at.
We will build a simple JAX-RS 2.0 server using great Apache CXF library. For the client side, we will use JAX-RS 2.0 client API and by utilizing Zipkin we will trace all the interactions between the client and the server (as well as everything happening on server side). To make an example a bit more illustrative, we will pretend that server uses some kind of database to retrieve the data. Our code will be a mix of pure Java and a bit of Scala (the choice of Scala will be cleared up soon).
One additional dependency in order for Zipkin to work is Apache Zookeeper. It is required for coordination and should be started in advance. Luckily, it is very easy to do:
Now back to Zipkin. Zipkin is written in Scala. It is still in active development and the best way to start off with it is just by cloning its GitHub repository and build it from sources:
git clone https://github.com/twitter/zipkin.git
From architectural prospective, Zipkin consists of three main components:
- collector: collects traces across the system
- query: queries collected traces
- web: provides web-based UI to show the traces
To run them, Zipkin guys provide useful scripts in the bin folder with the only requirement that JDK 1.7 should be installed:
- bin/collector
- bin/query
- bin/web
Let's execute these scripts and ensure that every component has been started successfully, with no stack traces on the console (for curious readers, I was not able to make
Zipkin work on Windows so I assume we are running it on Linux box). By default,
Zipkin web UI is available on port
8080. The storage for traces is embedded
SQLite engine. Though it works, the better storages (like awesome
Redis) are available.
The preparation is over, let's do some code. We will start with JAX-RS 2.0 client part as it's very straightforward (ClientStarter.java):
package com.example.client;
import javax.ws.rs.client.Client;
import javax.ws.rs.client.ClientBuilder;
import javax.ws.rs.core.MediaType;
import javax.ws.rs.core.Response;
import com.example.zipkin.Zipkin;
import com.example.zipkin.client.ZipkinRequestFilter;
import com.example.zipkin.client.ZipkinResponseFilter;
public class ClientStarter {
public static void main( final String[] args ) throws Exception {
final Client client = ClientBuilder
.newClient()
.register( new ZipkinRequestFilter( "People", Zipkin.tracer() ), 1 )
.register( new ZipkinResponseFilter( "People", Zipkin.tracer() ), 1 );
final Response response = client
.target( "http://localhost:8080/rest/api/people" )
.request( MediaType.APPLICATION_JSON )
.get();
if( response.getStatus() == 200 ) {
System.out.println( response.readEntity( String.class ) );
}
response.close();
client.close();
// Small delay to allow tracer to send the trace over the wire
Thread.sleep( 1000 );
}
}
Except a couple of imports and classes with Zipkin in it, everything should look simple. So what those ZipkinRequestFilter and ZipkinResponseFilter are for? Zipkin is awesome but it's not a magical tool. In order to trace any request in distributed system, there should be some context passed along with it. In REST/HTTP world, it's usually request/response headers. Let's take a look on ZipkinRequestFilter first (ZipkinRequestFilter.scala):
package com.example.zipkin.client
import javax.ws.rs.client.ClientRequestFilter
import javax.ws.rs.ext.Provider
import javax.ws.rs.client.ClientRequestContext
import com.twitter.finagle.http.HttpTracing
import com.twitter.finagle.tracing.Trace
import com.twitter.finagle.tracing.Annotation
import com.twitter.finagle.tracing.TraceId
import com.twitter.finagle.tracing.Tracer
@Provider
class ZipkinRequestFilter( val name: String, val tracer: Tracer ) extends ClientRequestFilter {
def filter( requestContext: ClientRequestContext ): Unit = {
Trace.pushTracerAndSetNextId( tracer, true )
requestContext.getHeaders().add( HttpTracing.Header.TraceId, Trace.id.traceId.toString )
requestContext.getHeaders().add( HttpTracing.Header.SpanId, Trace.id.spanId.toString )
Trace.id._parentId foreach { id =>
requestContext.getHeaders().add( HttpTracing.Header.ParentSpanId, id.toString )
}
Trace.id.sampled foreach { sampled =>
requestContext.getHeaders().add( HttpTracing.Header.Sampled, sampled.toString )
}
requestContext.getHeaders().add( HttpTracing.Header.Flags, Trace.id.flags.toLong.toString )
if( Trace.isActivelyTracing ) {
Trace.recordRpcname( name, requestContext.getMethod() )
Trace.recordBinary( "http.uri", requestContext.getUri().toString() )
Trace.record( Annotation.ClientSend() )
}
}
}
A bit of Zipkin internals will make this code superclear. The central part of Zipkin API is Trace class. Every time we would like to initiate tracing, we should have a Trace Id and the tracer to actually trace it. This single line generates new Trace Id and register the tracer (internally this data is held in thread local state).
Trace.pushTracerAndSetNextId( tracer, true )
Traces are hierarchical by nature, so do Trace Ids: every Trace Id could be a root or part of another trace. In our example, we know for sure that we are the first and as such the root of the trace. Later on the Trace Id is wrapped into HTTP headers and will be passed along the request (we will see on server side how it is being used). The last three lines associate the useful information with the trace: name of our API (People), HTTP method, URI and most importantly, that it's the client sending the request to the server.
Trace.recordRpcname( name, requestContext.getMethod() )
Trace.recordBinary( "http.uri", requestContext.getUri().toString() )
Trace.record( Annotation.ClientSend() )
The ZipkinResponseFilter does the reverse to ZipkinRequestFilter and extract the Trace Id from the request headers (ZipkinResponseFilter.scala):
package com.example.zipkin.client
import javax.ws.rs.client.ClientResponseFilter
import javax.ws.rs.client.ClientRequestContext
import javax.ws.rs.client.ClientResponseContext
import javax.ws.rs.ext.Provider
import com.twitter.finagle.tracing.Trace
import com.twitter.finagle.tracing.Annotation
import com.twitter.finagle.tracing.SpanId
import com.twitter.finagle.http.HttpTracing
import com.twitter.finagle.tracing.TraceId
import com.twitter.finagle.tracing.Flags
import com.twitter.finagle.tracing.Tracer
@Provider
class ZipkinResponseFilter( val name: String, val tracer: Tracer ) extends ClientResponseFilter {
def filter( requestContext: ClientRequestContext, responseContext: ClientResponseContext ): Unit = {
val spanId = SpanId.fromString( requestContext.getHeaders().getFirst( HttpTracing.Header.SpanId ).toString() )
spanId foreach { sid =>
val traceId = SpanId.fromString( requestContext.getHeaders().getFirst( HttpTracing.Header.TraceId ).toString() )
val parentSpanId = requestContext.getHeaders().getFirst( HttpTracing.Header.ParentSpanId ) match {
case s: String => SpanId.fromString( s.toString() )
case _ => None
}
val sampled = requestContext.getHeaders().getFirst( HttpTracing.Header.Sampled ) match {
case s: String => s.toString.toBoolean
case _ => true
}
val flags = Flags( requestContext.getHeaders().getFirst( HttpTracing.Header.Flags ).toString.toLong )
Trace.setId( TraceId( traceId, parentSpanId, sid, Option( sampled ), flags ) )
}
if( Trace.isActivelyTracing ) {
Trace.record( Annotation.ClientRecv() )
}
}
}
Strictly speaking, in our example it's not necessary to extract the Trace Id from the request because both filters should be executed by the single thread. But the last line is very important: it marks the end of our trace by saying that client has received the response.
Trace.record( Annotation.ClientRecv() )
What's left is actually the tracer itself (Zipkin.scala):
package com.example.zipkin
import com.twitter.finagle.stats.DefaultStatsReceiver
import com.twitter.finagle.zipkin.thrift.ZipkinTracer
import com.twitter.finagle.tracing.Trace
import javax.ws.rs.ext.Provider
object Zipkin {
lazy val tracer = ZipkinTracer.mk( host = "localhost", port = 9410, DefaultStatsReceiver, 1 )
}
If at this point you are confused what all those traces and spans mean please look through this documentation page, you will get the basic understanding of those concepts.
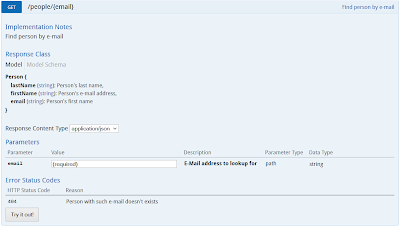
At this point, there is nothing left on the client side and we are good to move to the server side. Our JAX-RS 2.0 server will expose the single endpoint (PeopleRestService.java):
package com.example.server.rs;
import java.util.Arrays;
import java.util.Collection;
import java.util.concurrent.Callable;
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import com.example.model.Person;
import com.example.zipkin.Zipkin;
@Path( "/people" )
public class PeopleRestService {
@Produces( { "application/json" } )
@GET
public Collection< Person > getPeople() {
return Zipkin.invoke( "DB", "FIND ALL", new Callable< Collection< Person >>() {
@Override
public Collection call() throws Exception {
return Arrays.asList( new Person( "Tom", "Bombdil" ) );
}
} );
}
}
As we mentioned before, we will simulate the access to database and generate a child trace by using Zipkin.invoke wrapper (which looks very simple, Zipkin.scala):
package com.example.zipkin
import java.util.concurrent.Callable
import com.twitter.finagle.stats.DefaultStatsReceiver
import com.twitter.finagle.tracing.Trace
import com.twitter.finagle.zipkin.thrift.ZipkinTracer
import com.twitter.finagle.tracing.Annotation
object Zipkin {
lazy val tracer = ZipkinTracer.mk( host = "localhost", port = 9410, DefaultStatsReceiver, 1 )
def invoke[ R ]( service: String, method: String, callable: Callable[ R ] ): R = Trace.unwind {
Trace.pushTracerAndSetNextId( tracer, false )
Trace.recordRpcname( service, method );
Trace.record( new Annotation.ClientSend() );
try {
callable.call()
} finally {
Trace.record( new Annotation.ClientRecv() );
}
}
}
As we can see, in this case the server itself becomes a client for some other service (database).
The last and most important part of the server is to intercept all HTTP requests, extract the Trace Id from them so it will be possible to associate more data with the trace (annotate the trace). In Apache CXF it's very easy to do by providing own invoker (ZipkinTracingInvoker.scala):
package com.example.zipkin.server
import org.apache.cxf.jaxrs.JAXRSInvoker
import com.twitter.finagle.tracing.TraceId
import org.apache.cxf.message.Exchange
import com.twitter.finagle.tracing.Trace
import com.twitter.finagle.tracing.Annotation
import org.apache.cxf.jaxrs.model.OperationResourceInfo
import org.apache.cxf.jaxrs.ext.MessageContextImpl
import com.twitter.finagle.tracing.SpanId
import com.twitter.finagle.http.HttpTracing
import com.twitter.finagle.tracing.Flags
import scala.collection.JavaConversions._
import com.twitter.finagle.tracing.Tracer
import javax.inject.Inject
class ZipkinTracingInvoker extends JAXRSInvoker {
@Inject val tracer: Tracer = null
def trace[ R ]( exchange: Exchange )( block: => R ): R = {
val context = new MessageContextImpl( exchange.getInMessage() )
Trace.pushTracer( tracer )
val id = Option( exchange.get( classOf[ OperationResourceInfo ] ) ) map { ori =>
context.getHttpHeaders().getRequestHeader( HttpTracing.Header.SpanId ).toList match {
case x :: xs => SpanId.fromString( x ) map { sid =>
val traceId = context.getHttpHeaders().getRequestHeader( HttpTracing.Header.TraceId ).toList match {
case x :: xs => SpanId.fromString( x )
case _ => None
}
val parentSpanId = context.getHttpHeaders().getRequestHeader( HttpTracing.Header.ParentSpanId ).toList match {
case x :: xs => SpanId.fromString( x )
case _ => None
}
val sampled = context.getHttpHeaders().getRequestHeader( HttpTracing.Header.Sampled ).toList match {
case x :: xs => x.toBoolean
case _ => true
}
val flags = context.getHttpHeaders().getRequestHeader( HttpTracing.Header.Flags ).toList match {
case x :: xs => Flags( x.toLong )
case _ => Flags()
}
val id = TraceId( traceId, parentSpanId, sid, Option( sampled ), flags )
Trace.setId( id )
if( Trace.isActivelyTracing ) {
Trace.recordRpcname( context.getHttpServletRequest().getProtocol(), ori.getHttpMethod() )
Trace.record( Annotation.ServerRecv() )
}
id
}
case _ => None
}
}
val result = block
if( Trace.isActivelyTracing ) {
id map { id => Trace.record( new Annotation.ServerSend() ) }
}
result
}
@Override
override def invoke( exchange: Exchange, parametersList: AnyRef ): AnyRef = {
trace( exchange )( super.invoke( exchange, parametersList ) )
}
}
Basically, the only thing this code does is extracting Trace Id from request and associating it with the current thread. Also please notice that we associate additional data with the trace marking the server participation.
Trace.recordRpcname( context.getHttpServletRequest().getProtocol(), ori.getHttpMethod() )
Trace.record( Annotation.ServerRecv() )
To see the tracing in live, let's start our server (please notice that sbt should be installed), assuming all Zipkin components and Apache Zookeeper are already up and running:
sbt 'project server''run-main com.example.server.ServerStarter'
then the client:
sbt 'project client''run-main com.example.client.ClientStarter'
and finally open
Zipkin web UI at
http://localhost:8080. We should see something like that (depending how many times you have run the client):
Alternatively, we can build and run fat JARs using sbt-assembly plugin:
sbt assembly
java -jar server/target/zipkin-jaxrs-2.0-server-assembly-0.0.1-SNAPSHOT.jar
java -jar client/target/zipkin-jaxrs-2.0-client-assembly-0.0.1-SNAPSHOT.jar
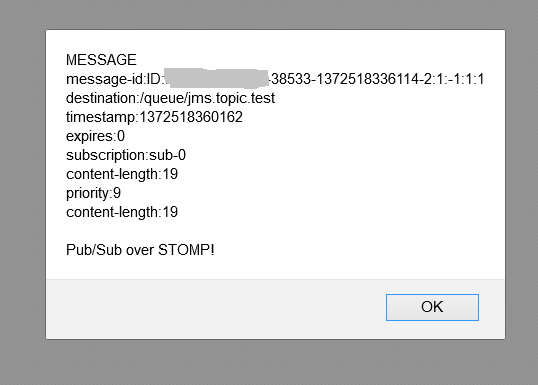
If we click on any particular trace, the more detailed information will be shown, much resembling client <-> server <-> database chain.
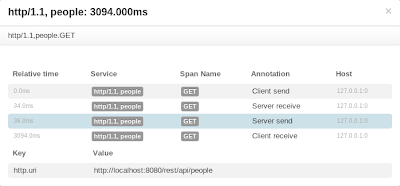
Even more details are shown when we click on particular element in the tree.
Lastly, the bonus part is components / services dependency graph.
As we can see, all the data associated with the trace is here and follows hierarchical structure. The root and child traces are detected and shown, as well as timelines for client send/receive and server receive/send chains. Our example is quite naive and simple, but even like that it demonstrates how powerful and useful distributed system tracing is. Thanks to Zipkin guys.
The complete source code is available on GitHub.